Title: You Only Look Once: Unified, Real-Time Object Detection Paper Link
Authors: Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
Association: University of Washington, Allen Institute for AI, Facebook AI Research
Submission: May 2016

Prior work on object detection repurposes classifiers to perform detection.
…………………………………………………………………………………………………………………
»> Background of Deep Learning in Medical Image Analysis
»> A Review: Robot-Assisted Endovascular Catheterization Technologies:
…………………………………………………………………………………………………………………
»> Image Registration Basic Knowledge
»> Image Registration Literature Review
»> Slice-To-Volume Medical Image Registration Background
…………………………………………………………………………………………………………………
Contributions
(1) frame object detection as a regression problem —> spatially separated bounding boxes and associated class probabilities. predicts bounding boxes and class probabilities directly from full images in one evaluation.
(2) frame detection as a regression problem —> A FAST real-time detectors no need a complex pipline.
(3) Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly (隐含地) encodes contextual (前后关系的) information about classes as well as their appearance.
Fast R-CNN can’t see the larger context (the entire image)

Background
“Humans glance (一瞥) at an image and instantly (promptly; 立即地;马上地;即刻地) know what objects are in the image, where they are, and how they interact. The human visual system is fast and accurate, allowing us to perform complex tasks like driving with little conscious thought. “
CNN based object detectors can be categorized into:
| one-stage detector | two-stage detectors |
|---|---|
| YOLO Reading Note | Faster R-CNN Reading Note |
| SSD Reading Note | R-CNN Reading Note |
| RetinaNet Reading Note | FPN Reading Note |
| OverFeat Reading Note |
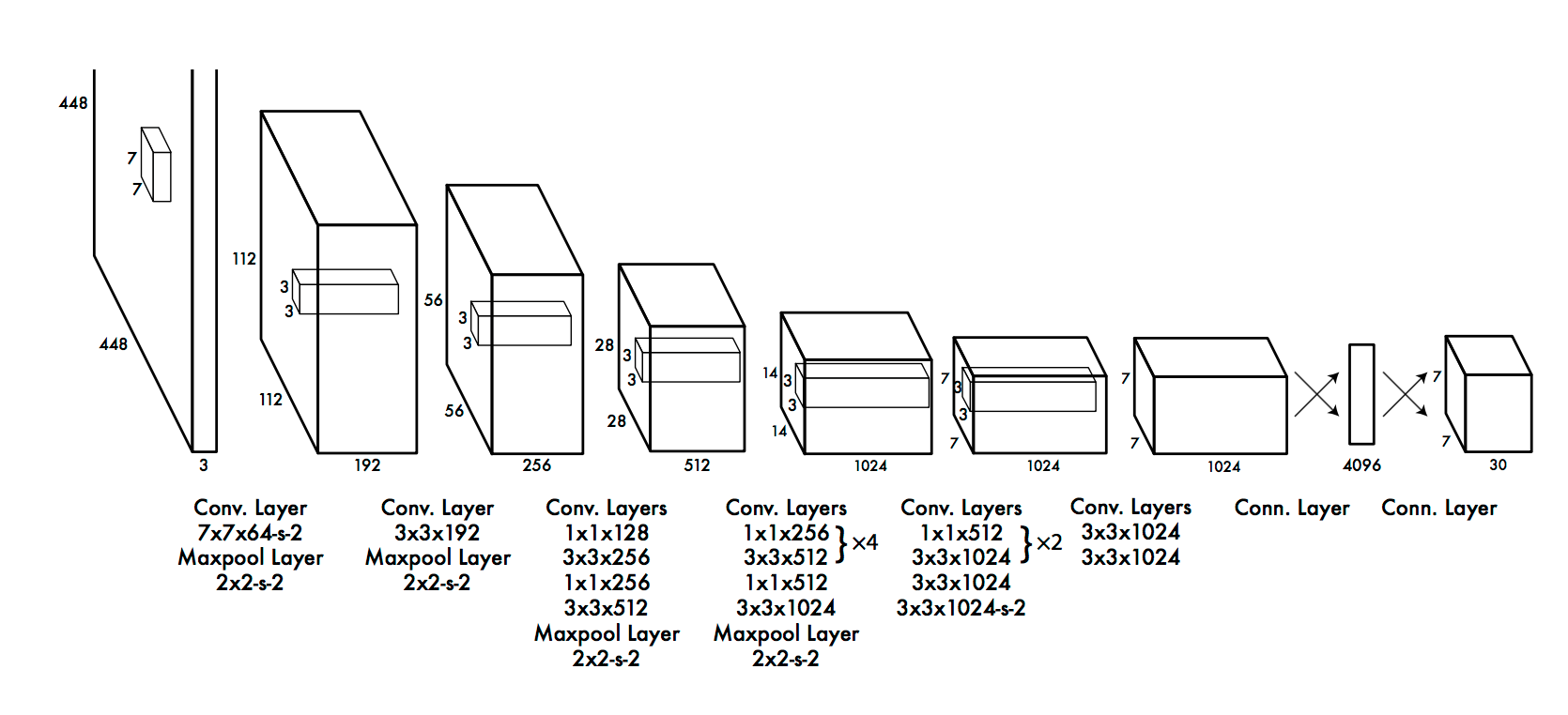
Network Design
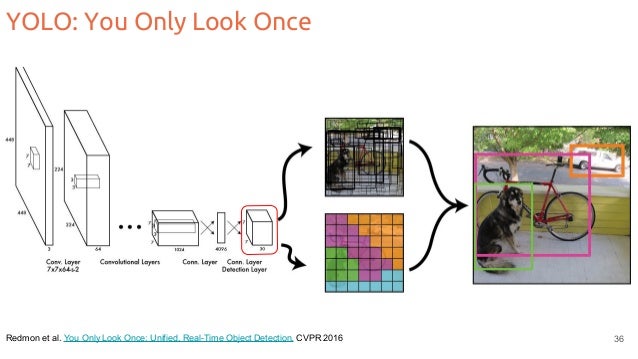
inspired by the GoogleNet model for image classification.
Limitations
“YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds. “
“Since our model learns to predict bounding boxes from data, it struggles to generalize to objects in **new or unusual **aspect ratios or configurations. Our model also uses rela- tively coarse features for predicting bounding boxes since our architecture has multiple downsampling layers from the input image. “
“Finally, while we train on a loss function that approximates detection performance, our loss function treats errors the same in small bounding boxes versus large bounding boxes. A small error in a large box is generally benign but a small error in a small box has a much greater effect on IOU. Our main source of error is incorrect localizations.”
Performance
*
Other Useful Info.
Object Detection helpful slides link (D2L5 Insight@DCU Machine Learning Workshop 2017)